索引底层原理
解释底层的索引的数据结构 - b+树
B+树
InnoDB 存储引擎中的 B+ 树索引。要介绍 B+ 树索引,就不得不提二叉查找树,
平衡二叉树和 B 树这三种数据结构。B+ 树就是从他们仨演化来的。
索引文件和数据文件 - innodb中 - 合二为一的 - 只有1个文件
索引文件和数据文件 - myisam中 - 分开独立的 - 俩个文件
二叉树

节点(每个圆圈圈)中存储了键(key - 主键索引列)和数据(data - 每一个行记录)。键对应 user 表中的 id,数据对应 user 表中的行数据。
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点。
如果我们需要查找 id=12 的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
id=12先和根节点[只有一个]key=10,发现id=12>id=10 - 顺利向着根节点的右边去匹配
id=12和非叶节点id=13的进行匹配,顺利执行id=13的左边
id=12和id=12比较 - 两者是相同的.由于每个节点除了保存key还保存了value[行记录 - 行真实的行数据]
直接将这个节点的value直接取出来了.
总结 - 总共匹配了3次就可以顺利找到我们的数据.
如果没有创建二叉树索引.查找id=12,必然会进行全表扫描.从表的第一行向下找.最好的状态也得找6次
平衡二叉树
二叉树带来的弊端
二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值
二叉树在极端的场景下有可能成为一个链表的结构[链表的查询效率很低很低的.]
查找id=12,”链表结构”,只能从链表的头节点开始查找,最佳状态也得寻找找了5次.

AVL
为了解决这个问题[防止二叉树变成了链表结构导致查询效率依然低下],我们需要保证二叉查找树一直保持平衡,就需要用到平衡二叉树.
平衡二叉树又称 AVL 树,在满足二叉查找树特性的基础上,要求每个节点的左右子树的高度差不能超过 1。
下面是平衡二叉树和非平衡二叉树的对比:

只要找到任何一个节点的左右子树高度差的绝对值大于1 - 非平衡二叉树
1 | 节点45 - 左子树高度 = 左边的子节点的个数 = 2 |
B树
平衡二叉树暴露出来了一些缺点:
每个节点仅仅保存一个key-value键值对[每个节点可保存的键值对数据太少了].每次进行查询的时候,实际上都是需要从磁盘中读取数据的.
那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块
由于每个节点可保存的数据不多,仅仅保存了一个key-value.在查找数据的过程中,它就不断去和磁盘进行IO交互.
导致平衡二叉树的节点比较多.也就导致了平衡二叉树的高度比较高 - 导致比较的次数比较多 - 频繁和IO进行交互 - 查询效率低下.

为了解决平衡二叉树的高度太高问题.B树登场了.
B树特点
根节点[第一页] - 永驻内存.
每个节点可以保存多个key-value - 导致子节点也会增多.B树又矮又胖.
没有子节点的节点 - 叶节点,有子节点的节点 - 非叶节点
B树的m阶 - m值就是看它最大的子节点的个数 - 3 , 下面的图代表的就是3阶b树.
如果有10亿条数据,只需要和磁盘进行交互2次.把磁盘块中的一页数据[16kb]全部加载到内存中.
页page的概念 - 那我们每查找一次数据就需要从磁盘中读取一个节点,也就是我们说的一个磁盘块
读取的单位是 - 页 - 1页的磁盘块的数据大小是16kb,每个节点可以更多的key-value
页与也之间是一个链表的结构
查找id=28的数据 - 磁盘交互了3次
①id=28到第一页中进行匹配,发现id=28在17和35之间,获取p2指针.p2指向到页3
②定位到页3,发现id=28在26~30之间,继续拿到p2指针,p2指向的是页8
③定位到页8,顺利匹配查找到id=28这条数据

B+树
是Innodb和myisam存储引擎中索引底层的数据结构 - B+树
B树中每个节点中不仅仅存储key[索引列值,主键列值],还存储了数据.因为数据库中的页的大小是固定的[Innodb默认是16kb],
导致每个节点的存储资源有点浪费了.
B+树和B树的重要区别就是
B+树中非叶节点,仅仅保存了key值[索引列,主键列值],没有保存数据.每个非叶节点可以保存更多的key
B+树中索引的所有的数据都放在了叶子节点中,而且是按照顺序排列的.
- **页与页之间是双向链表结构,**叶节点中的每个数据节点单向链表
- 下面这个图展示的是Innodb中的索引的结构.并不是Myisam中索引的结构
- 以下图示本质上就是聚簇索引[主键列索引]的方式 - key - 主键列

聚簇索引和非聚簇索引
在上节介绍 B+ 树索引的时候,我们提到了图中的索引其实是聚集索引的实现方式。
那什么是聚集索引呢?在 MySQL 中,B+ 树索引按照存储方式的不同分为聚集索引和非聚集索引。
这里我们着重介绍 InnoDB 中的聚集索引和非聚集索引:
聚集索引(聚簇索引):以 InnoDB 作为存储引擎的表,表中的数据都会有一个主键,即使你不创建主键,系统也会帮你创建一个隐式的主键。
这是因为 InnoDB 是把数据存放在 B+ 树中的,而 B+ 树的键值就是主键,在 B+ 树的叶子节点中,存储了表中所有的数据。
这种以主键作为 B+ 树索引的键值而构建的 B+ 树索引,我们称之为聚集索引。
非聚集索引(非聚簇索引):以主键以外的列值作为键值构建的 B+ 树索引,我们称之为非聚集索引。
非聚集索引与聚集索引的区别在于非聚集索引的叶子节点不存储表中的数据,而是存储该列对应的主键,想要查找数据我们还需要根据主键再去聚集索引中进行查找,这个再根据聚集索引查找数据的过程,我们称为回表。
聚簇索引存储和查找
- 先到非叶节点找到索引列所在的页位置
- 根据页位置定位到叶节点的位置
- 叶节点中根据索引列的值找出数据

1 | select * from xx where id>=18 and id<41; |
非聚簇索引存储和查找
B+树的结构
表结构:id age name
id - 主键列 - 默认是聚簇索引列 - 主键列
name - 非聚簇索引列 - 索引列 - 辅助索引

非聚簇索引 - 非主键列索引 - name列创建了索引 - 辅助索引.
结构:
根节点 - 一页数据 - 非聚簇索引列值 - name
非叶节点 - 非聚簇索引列值
页节点存储的东西 - name索引列以及该列对应的主键列值. - 这是和聚簇索引最大的一个不同点
它和聚簇索引最大的区别是页节点中没有存储最终的数据.而是存储的是键值对x-y
x就是非聚簇索引列值,y是对应的主键列值.
非聚簇索引的查找方式:
按照B+树的查找流程 - 确认name=’Bob’的具体位置
由于非聚簇索引的结构中叶节点仅仅保存了name-主键列值
先根据name=’Bob’这个条件找到对应的主键列值id=15
要进行”回表操作”

继续拿着主键列id=15到索引的结构中继续查找一次 - “一次回表查找”.
id也是聚簇索引 - B+树的结构 - 叶子节点中存储的就是数据.
根据聚簇索引列的查找方式 - id=15的叶节点 - 拿到里面的数据
非聚簇索引列查找一定会回表?????
未必 - 因为非叶节点中存储的就是索引列值.
查询
select id from xxx where name=’Bob’;
select name from xxx where name=’Bob’;不需要回表了.这条语句查询的结果name已经在非聚簇索引的非叶节点中保存了.
回表
根据一个非聚簇索引列查找 - 优先先到非聚簇索引的B+树中找到该列对应的主键列值[聚簇索引列值]
再拿着这个聚簇索引列的值再去到聚簇索引列的B+树中再查找一次
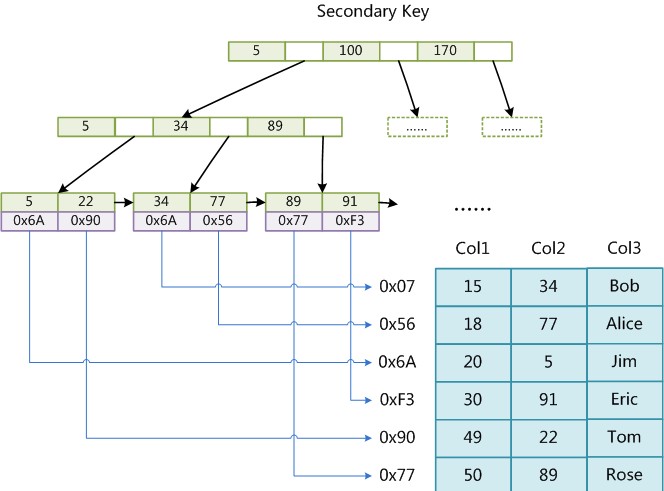
myisam中的索引特点
索引的本质就是一个键值对key-value
key - 索引列值,value - 数据行的物理地址.
主键列索引/辅助索引 -> 两颗独立的B+树,都是索引列值对应的行记录的物理地址.
innodb中索引和数据合并到一个文件中
myisam中索引和数据是单独的俩个文件,分别是索引文件和数据文件.
myisam中采用的是”非聚集的方式”
无论是聚簇索引还是非聚簇索引,查找方式是一样.
采用的也是B+树的结构**.只是叶节点中存储的是索引的列值以及该对应的行记录的地址.**
需要再根据行记录地址到表中进行定位[回表]
2
3
4
5
6
非主键列 - key是允许重复的.
select * from xxx where id=5;
1. 先到B+树找到找到id=5对应的节点 - 取出里面的行记录的物理地址0x6a
2. 回表 - 直接根据行记录的物理地址直接定位到具体的一行.